
Pervasive computing is the holy grail of computer and network technology. It promises a world where communications and computation are everywhere, instantly available, virtually free, and capable of almost anything. Why doesn't pervasive computing exist today?
The problem is complexity. Unless a system is extremely well designed, as it grows larger it becomes harder to ensure correct operation. In ad hoc networks, for example, this complexity takes the form of system-wide flooding that overwhelms usable bandwidth. Complexity rears its head in chip design, large software projects, and large organizations such as the government, the military, and networks.
As a system grows bigger, the only way to ensure its correct operation is to impose additional structure and rules. Examples of these are design rules, functional blocks, bureaucratic procedures, rules of engagement, and protocols (e.g., TCP/IP). The imposed structure and rules serve to restrict the range of possible behavior for those units that make up the system. The bigger the system, the greater the restrictions, and the more time required for system management and maintenance. The time and resources spent managing these types of systems raise the costs of scaling far above the benefits it provides. Costs will kill a pervasive network as certainly as wholesale flooding; in a network of hundreds of billions of nodes, even the smallest cost per node adds up to a very large total cost. The marginal costs of adding a node to the network have to effectively be zero.
Requirements of a Pervasive Communication Network
Needing no human intervention is not enough. A pile of rocks doesn't need human intervention, but it's not very useful. A pervasive network should possess, at a minimum, the following characteristics.
It should be self-configuring. Regardless of size, structure, or mobility the network should be able to organize itself such that nodes in the network can establish connections and communicate with one another and the outside world. The network should organize wired nodes as easily as it does wireless nodes.
It should be self-healing. Pervasive networks should be capable of instant repair and re-routing around problem areas. If a network is split into parts, they should operate independently; if the parts are joined, they should operate as one.
It should support heterogeneous nodes. An extremely low-power mote should be able to share a network with a supercomputer. Any node should be able to connect to, or accept connections from, any node in a network of millions.
Connectivity should be instantaneous. Two new nodes joining a network of millions should be able to connect to each other across that network within moments.
It should have low bandwidth. The vast majority of available bandwidth must be set aside for actual payload packets.
It should require no human intervention. There should be no user management needed anywhere in the network, ever. This requirement keeps maintenance costs to an absolute minimum. For networks involving billions of nodes, even very limited human intervention on a per-node basis would make pervasive communication too expensive.
Current Approaches Don't Scale
Although this fact is not well known outside companies specializing in mesh networks, no current ad hoc point-to-point mesh network approach can scale past a trivial number of nodes (current mesh networks are limited to 400 or fewer).
There are three broad classes of networking protocols: flat, hierarchical, and location based.
Common flat routing protocols are ad hoc on-demand direct vector, destination-sequenced distance vector, fisheye state routing, and topology broadcast reverse-path forwarding. Flat routing protocols face scaling limitations as a result of how connections are established and maintained. A node X can establish a connection to another node Y in the network only if every node in the network is aware of how to get to Y. This causes network control traffic to grow exponentially as a function of network size. Large networks become impossible since all network bandwidth is needed for control bandwidth messages.
Hierarchical routing protocols break the network into groups and then use a flat routing protocol to organize those groups. The groups are then broken into subgroups and so on. Common examples are zone routing protocol, hierarchical state routing, and landmark ad hoc routing. Hierarchical routing can delay but not avoid the problems of flat routing. It can also cause suboptimal routes to be formed.
Location-based routing such as GeoCast (location dependent), location-aided routing, distance routing effect algorithm for mobility, or greedy perimeter stateless routing uses the physical position of a node in the network to route packets to that node. However, the most direct physical route is often not the fastest, and if there isn't an "as the crow flies" alternative the protocol must perform a flood, sending out packets to all nodes. Finally, if a node changes location, the connection to that node will be broken and another flood is required to establish its new location.
The First Scalable Routing Approach
Ad hoc mesh networks appear very, very complex; they have lots of connections per node, the node relationships can change moment to moment, loops can form, and routes can break. These are formidable obstacles to scaling this type of network.
OrderOne Networks has developed a new approach to routing that meets the requirements for a pervasive communication network. We wanted to find simplicity in mesh networks, so we decided to work with only the absolute minimum of network knowledge: 1) that a node exists and 2) which node directly connected to a node is the first and best step to that other node (see Figure 1). We do not need to know any paths or routes through the network. Note that "best step" is defined by several factors, including SNR, bandwidth, and reliability.
 Figure 1. Node A chooses either node B or node C as its next best step to nodes in the ad hoc network. Since node B is chosen most often, it is considered node A's next best step to the top of the hierarchy. |
Recognizing that a large network cannot have an imposed structure, we then had to find a natural structure within the network. Structure is built on differences. The obvious ones are each node's knowledge of other nodes and each node's link/bandwidth differences.
Since our approach uses a distance vector protocol for routing packets, a node needs to pick as its next best step whatever node directly connected to it gives the best route to the most other nodes (see Figure 2). This process is dynamic and continually reviewed.
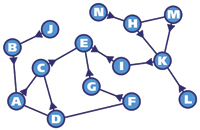 Figure 2. Every node in the network picks a neighbor node that is used as its "next best step" to the most other nodes. This neighbor node then becomes the node's choice for its next best step to the top of the hierarchy. |
By having each node point to whichever of its neighbors is the next best step to the most other nodes, a process is generated that ultimately leads to two nodes pointing to each other as the "next best step" to the most other nodes. This pair forms the top of the hierarchy of knowledge of nodes and the core of the network, shown in Figure 3.
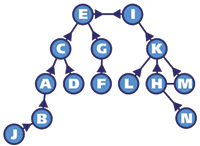 Figure 3. This process generates a hierarchy that is much easier to see if the network is rearranged. In this example the network is identical to that shown in Figure 2, but the layout of the nodes has been changed. |
This is a hierarchy based on knowing the next best step to the most other nodes. No node knows where the center of the network is; it knows only its next best step to it. This hierarchy will instantly change and adjust to match the network as the network changes. If a network is divided, each portion will have a separate center. If two networks merge, one center will be formed.
We can exploit this characteristic to let nodes connect almost instantly, even in very large networks, without the need for a global flood. The mechanism to do this is called a high-speed propagation path (HSPP).
The HSPP can either push node knowledge toward the top of the hierarchy or pull node knowledge from the top of the hierarchy down. Every node uses an HSPP to push knowledge of itself directly toward the top of this hierarchy (see Figure 4). In this way a route to every node will be sent toward the center of the network, without the need for a global flood.
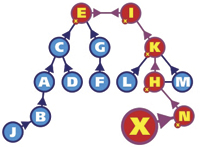 Figure 4. If a new node X connects to node N, it will push a route to itself up the hierarchy. Every node in the network maintains route information on those nodes between itself and the top of the hierarchy. |
This process creates an increasing density of node knowledge toward the core. Since the core is formed around those nodes with greater capacity and connectivity, the network can easily handle the resulting increased load.
If a node needs to establish a connection it will send an HSPP request toward the center of the network looking for knowledge of a particular node (see Figure 5). For example, if the distance from the node to the top of the hierarchy is 5 hops, only about 90 bytes in total (5 hops x 18 bytes, where 18 bytes is the size of the identification and HSPP packets) would travel within the whole network to build that first connection. This number could be tweaked to be even lower if needed.
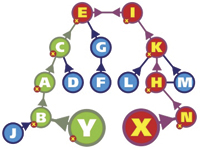 Figure 5. If a new node Y wants to connect to node X, it will search the nodes between itself and the top of the hierarchy. This allows a first path to its destination to be built without using a global flood to query all the nodes in the network. |
If a node already has established a route to its destination, then that route will be used immediately and no packets will have to be routed through the center of the network.
The core and HSPPs are used only to establish that first path. By flooding around this first suboptimal path, we can achieve rapid convergence to the optimal path, shown in Figure 6.
 Figure 6. Route updates for both nodes X and Y are flooded out around the path that node X and node Y are using to communicate. This allows the path to converge on its optimal route through the network, again without using a global flood. |
Note that storing node knowledge is very efficient. An average desktop PC could easily know of millions of nodes. Control bandwidth is capped at 5%–10% of all network bandwidth, ensuring that the vast majority of bandwidth is available for user packets.
The HSPP mechanism allows low-power sensors and motes to piggyback on the capabilities of higher-capacity nodes. Since a sensor can use the HSPP to push knowledge of itself up the hierarchy, it can ensure that all nodes in the network can connect to it. By using an HSPP to request route knowledge to be sent to it, a sensor can ensure that it will hear only about those nodes that it wants to connect to.
The unique attributes of this approach make it the first in a class of new routing protocols capable of scaling to very large size without significant limitations.
What Do Pervasive Networks Allow?
So let's throw out some pervasive applications. For weather purposes we might have one or two sensors for every square kilometer of planetary surface. Everyone could be tagged with health-related sensors and carry a personal communicator. Each home could be networked and every vehicle could be connected, from trains to bicycles.
Municipal networks will exist for lighting, traffic control, utilities metering and reading, security and traffic cameras, and local wireless access points. Border security will add hundreds of millions and billions of sensors. Business applications could double all the above.
With networks being transparent and pervasive, many more uses will be found and freely used because—why not?
Authors' note: This network method has been tested successfully in simulation to several thousand nodes. By the time this article is published, it will have been tested in radios. We are in discussions for installations in North America and the Middle East.
David Davies is COO and Chris Davies is CTO, OrderOne Networks, Orangeville, ON, Canada; 519-941-4581, [email protected], [email protected], www.orderonenetworks.com.