

The software application described in this article is used to create large sensor networks very easily, and to any size, recognizing that development can be costly and time-consuming. We realize that users need reliability, high security, individual device identification, and access across multiple networks, and our software provides these qualities. The software is also designed with the understanding that in a network of hundreds, thousands, or millions of devices those devices will have the lowest cost and lowest capacity possible, and therefore this software is designed to work with very-low-bandwidth, very-low-CPU devices. Any digital data can be transmitted if the devices used are appropriate, whether those data are in the form of meter readings, text, or video. It also presents a cost-effective alternative to the use of cellphone and wired networks.
Intended applications include utility network metering, monitoring, and management; security systems around nuclear and other power-generating stations; urban surveillance; transit systems, railroads, and other highly mobile networks; traffic monitoring and management; pipeline surveillance; oversight of large industrial operations and facilities; seismic networks; and networks of unusual and difficult topologies.
Large sensor networks can be used far more widely than previously supposed. Because they seemed either impossible or impossibly expensive, many applications for such networks have not been considered because of the networking challenges involved. With OrderOne Embedded these applications are now possible.
EDITOR'S NOTE: Please refer to the glossary at the end of the article to find definitions for unfamiliar terms.
The Software Framework
The OrderOne Scalable Embedded framework has been designed from the ground up to meet the challenges of extremely large networks that must operate on very limited embedded devices in many different applications. It is a framework to build very-large-scale embedded applications for real-world use. All required software functions are cleanly abstracted, such as encryption, tunneling, routing, reliable messaging, logging, name resolution, and forwarding.
It is specifically designed for embedded devices and uses a single primary thread. It uses CPU and memory efficiently, is endian-independent, and is IP-address independent. Its modular design (Figure 1) enables rapid adaption to varying applications. In addition, it is designed to integrate both emulated and real devices to enable easier system design and testing.
 Figure 1. A block diagram of OrderOne Scalable Embedded |
Limited CPU usage. OrderOne Scalable Embedded performs all its core activities in a single process with a single OS thread. Within this core process are multiple user threads that are cooperatively threaded, requiring a thread to explicitly yield before execution will pass to another thread. Cooperative threading is commonly used in low-power embedded devices because it enables very fast context switching; low-latency, high-speed message passing; explicit control over the scheduler; and reduced CPU usage.
The OS has no knowledge of the cooperative threads held within the core process. It sees the process as having a single thread. All activities that have the potential to block or delay execution are handled using asynchronous communication so that information is returned without waiting or blocking other activities.
This single process forks into two other processes with changed scheduling priorities (in software parlance they are "nice'd to a very low priority"). These forked processes handle the Diffie-Hellman encryption computations and the system shell interaction, respectively. Communication with these processes is via asynchronous socket communication.
The entire OrderOne Scalable Embedded application consists of four files:
- a core executable that reads a configuration file and then loads the appropriate runtime module
- a kernel module that handles the AES-128 encryption and packet forwarding
- a configuration file containing the configuration parameters for the core executable and the runtime loadable module
- a runtime loadable module containing the logic specific to the required task (e.g., utility grid, transit system, or tactical)
There are no other dependencies aside from libc, the C standard library. Diffie-Hellman and AES encryption are included in the core executable and the kernel module, respectively. The core executable, kernel module, and runtime loadable module have all been written in C with no floating-point math for maximum performance.
Encryption. Every packet generated by OrderOne Scalable Embedded is encrypted. Sessions between nodes exchange shared encryption keys using the Diffie-Hellman algorithm with a 1024-bit shared key. AES-128 encryption is then used to secure the session communication. Particular care is given to provide a constantly changing initialization vector (IV), which allows AES to encrypt identical data but generate a different output every time.
All packets are hashed using SHA-2 (a cryptographic hashing algorithm) to ensure that they have not been altered or corrupted in transit. Broadcast control packets are encrypted using AES-128 with a configurable preshared key (PSK).
No unique IPs or global DHCP server required. Unique IP assignment is a significant challenge for very-large-scale mesh network deployments. Unique IPs are needed to communicate between devices. The typical solution involves using IPv6 addresses because they can be randomly generated with a high percentage chance of uniqueness. However, using IPv6 addressing causes routing and forwarding overhead.
If IPv4 routing is required, a global DHCP server is often needed to assign unique IP addresses. The weakness of this approach is that if either the DHCP server or the external connectivity fails, then the devices will be unable to communicate. Additionally, because it is difficult to route before getting a valid network address, a broadcast flood of DHCP messages is needed. This can overwhelm a low-bandwidth or a very dense, higher-bandwidth network.
OrderOne Scalable Embedded uses IPv4 networking and a unique mechanism to avoid the need for unique IPv4 addresses or the use of a global DHCP server. Each node maps a locally unique IP to the locally unique IP addresses of the other nodes with which it has established a session. Through careful on-the-fly translation and the use of a local DHCP server, applications can connect seamlessly to the Internet (or external networks) as well as to devices and applications inside the network. For example, connecting via secure shell (ssh) to a device named "deviceABCD.internalnetwork" would result in the appropriate connection.
Layer 2 forwarding. All packets are forwarded as layer 2 packets. Encrypted sessions are established using the unique MAC address of the other device.
A single encrypted session can carry:
- reliable in-order messages between devices
- all data between the devices that established the session and other devices connected to them that are not running OrderOne Scalable Embedded
- system messages used by OrderOne Scalable Embedded
Routing. The OrderOne Networks routing protocol is integrated into OrderOne Networks Embedded where it provides scalable, low-bandwidth, low-CPU routing. It supports limits to the distribution of specific routes and the inclusion of extra developer-specific information with every route update.
Linux integration. OrderOne Scalable Embedded has been designed to fully utilize Linux networking to provide maximum flexibility to the application developer.
All iptables features such as NAT, port forwarding, masquerading, and mangling are available and operate identically to a base Linux installation. This capability allows the runtime loadable module to hide hundreds of devices behind a single IP address (using port forwarding and NAT) by issuing standard iptables commands.
Customization. All specific customization is limited to a runtime loadable module. For example, a sensor network application would be one loadable module (e.g., sensornetwork_v1.so) while the utility grid application would be another (e.g., grid_v1.so). These modules interact with the OrderOne Scalable Embedded core application through a well-defined interface. The loadable module is specified in the configuration file that is provided at runtime to the OrderOne Scalable Embedded application. This interface has been designed to provide maximum flexibility while simultaneously hiding as much detail as possible.
This approach allows both high performance and an easy path for targeting different market opportunities. For example, a simple "everyone connected to everyone" network takes about 30 lines of code.
Alternatively, sending a reliable in-order encrypted message to another device uses this API call:
void SYSTEM_sendMsg (void *mac,
void *pMsg,
uint32_t msgSize);
The first parameter specifies the MAC address of the other device and the next two specify the message. If a session is not currently present, one will be negotiated and then the message will be transferred automatically. The receiving node or device will be notified via a callback.
Integrated tunneling. OrderOne Scalable Embedded allows integrated tunneling for both control packets and user data through external networks such as the Internet. In contrast to standard GRE tunnels, OrderOne Scalable Embedded tunnels have been designed to allow multiple incoming connections to terminate on a single virtual tunnel interface.
As an example, each incoming tunnel from a leaf node can terminate on a single tunnel interface on a command node (Figure 2). Routing control packets generated by the command node on this interface will be sent to all leaf nodes; however, unicast data will be forwarded only to the specific node in question. Routing control packets generated on the leaf nodes would only be seen by the command node and not the other leaf nodes. This creates a near-ideal tunneling scenario to create massive networks that terminate cleanly into several Internet control nodes.
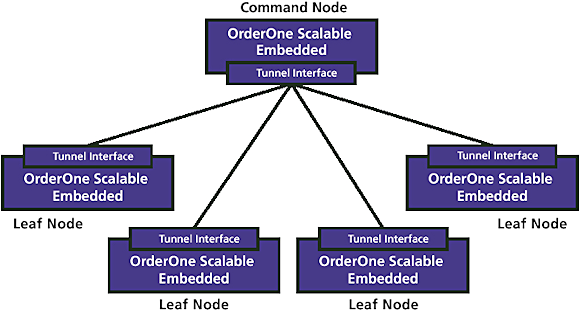 Figure 2. A network topology that uses tunneling |
Full Emulation
Using the CORE emulation framework (Figure 3) multiple emulated nodes may be configured and run in real time. These emulated devices run the same code as that on the actual devices. This capability allows the developer to rapidly test and debug the system using different network topologies, including those involving real-time mobility. These emulated nodes can also be connected to physical devices that may be present on the developer's desk to assess CPU usage and other metrics that are unavoidably device-dependent.
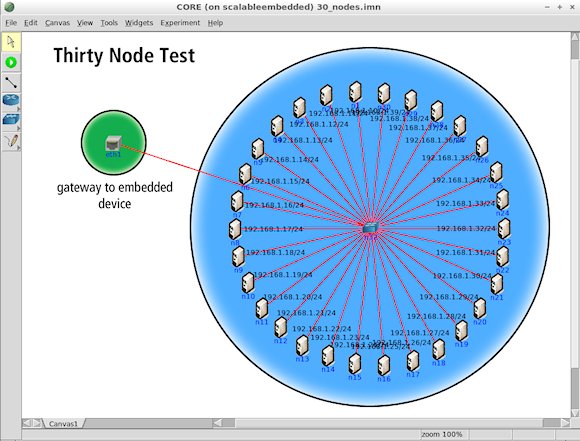 Figure 3. The CORE emulation framework used for testing |
As an example of testing on an embedded device, we used a Picostation 2 from Ubiquiti, which is an Atheros MIPS 4KC running at 180 MHz with 32 MB of RAM and 8 MB of flash memory.
The Picostation2 was connected to 30 virtual devices running on a laptop and then OrderOne Scalable Embedded was started on the Picostation2. The OrderOne protocol was configured to generate a packet once every second.
Results for the Picostation2:
- it took 1.7 s from launch for OrderOne to build routes to all 30 virtual devices
- it took 25 s from launch to build encrypted sessions with all 30 virtual devices
- after the sessions were built, user-space CPU usage was between 7% and 10% and additional kernel/system usage was between 3% and 6%.
- there were no routing drops while the sessions were being built
By having a large number of emulated nodes connected to a few actual devices the developer can create large stress-test environments involving lots of packet loss while using a small number of real devices.
Rapid Development
Rapid development was one of the key drivers in the development of OrderOne Scalable Embedded. A typical debug cycle should take less than a minute on a laptop running a virtual machine (VM) of Ubuntu. Here are the steps involved and the time required to build and run a modified version of the core:
- (2.1 s) issue a build command on the host machine that rsyncs the source code image to the Linux VM and then makes both the logic module and the core application
- (~3 s) move to the Linux VM window and press the play button on the emulation. CORE initializes the nodes and launches OrderOne Scalable Embedded.
That's it!
OrderOne Scalable Embedded has been thoroughly tested and is currently bug-free. In the future we intend to add features, both those already planned and those indicated from customer feedback. We see OrderOne Scalable Embedded as giving life to the market for very large-scale sensor networks that can range from a few hundred nodes to those spanning many millions of nodes.
ABOUT THE AUTHOR
David Davies is CEO for OrderOne Networks Ltd., Toronto, Canada. He can be reached at 416-732-6117, [email protected].
|
GLOSSARY abstraction—the process by which data and programs are defined using a representation similar in form to their meaning (semantics), while hiding away the implementation details AES-128 encryption—the Advanced Encryption Standard (AES) is a specification for the encryption of electronic data established by the U.S. National Institute of Standards and Technology (NIST) asynchronous communication—data are not transmitted at regular intervals, thus enabling a variable bit rate. The transmitter and receiver clock generators do not have to be exactly synchronized all the time. This enables very fast movement of messages as required, rather than at a predetermined rate configuration file—the file that sets the initial settings for some computer programs. Configuration files are used for user applications, server processes, and operating system settings control packets—a formatted unit of data carried by a packet-mode computer network. Computer communications links that do not support packets, such as point-to-point telecommunications links, transmit data as a series of bytes, characters, or bits cooperatively threaded—a software architecture that avoids the negative effects of preemptive threading, i.e., results in fewer errors caused by the untimely pre-empting of running processes CORE emulation framework—the Common Open Research Emulator (CORE) is an open-source network emulation framework. It uses existing OS virtualization techniques to build wired and wireless virtual networks where protocols and applications can be run without modification core executable—the parts of memory that initiate operations Diffie-Hellman computations—calculations required by the Diffie-Hellman encryption process, named after its inventors Whitfield Diffie and Martin Hellman embedded system—a computer system that is designed for specific control functions within a larger system encryption—the process of encoding messages (or information) in such a way that authorized parties can read it and eavesdroppers or hackers cannot endian independent—used to describe how bytes are ordered within a data item; endianness is then the same as byte order. Being endian independent avoids problems with software that will run on different operating systems that may be purely big-endian or little-endian explicit control over the scheduler—the occurrence of a process is not managed by predetermined rules, but by need and function-appropriate criteria forwarding—the process of finding the proper point to which the inputted data should be sent full emulation—the emulated behavior closely resembles the behavior of the real system. This focus on exact reproduction is in contrast to some other forms of computer simulation in which an abstracted model of a system is simulated global DHCP server—a network protocol that is used to configure network devices so that they can communicate on an IP-based network. It involves clients and a server operating in a client-server model GRE tunnels—Generic Routing Encapsulation (GRE) is a tunneling protocol that can encapsulate network layer protocols inside virtual point-to-point links over an IP-based network hashing—applying a data-mapping algorithm IP address independent—having a unique identifier but that identifier is not tied to the IP address iptables—the tables provided by the Linux kernel firewall—a configuration file that contains the configuration for the core executable and the runtime loadable module kernel module—a program that executes commands in the kernel, the bridge between applications and the actual data processing done at the hardware level. layer 2 packets—in the seven-layer OSI model of computer networking, the data link layer is layer 2. In the TCP/IP reference model it corresponds to, or is part of the link layer. The data link layer is the protocol layer that transfers data between adjacent network nodes in a wide area network (WAN) or between nodes on the same local area network (LAN) segment libc—the standard library for the C programming language logging—the process of recording events using a computer program, usually a software application low latency, high-speed message passing—very short waits between processes to enable very fast delivery of messages (instructions or data) mangling—a method of encoding the name and additional information about a function, structure, class, or another data type to increase the amount of information passed masquerading—ip masquerading allows a network to access another network via a single gateway, such as a WLAN router. The router translates all local IP addresses into the public IP address that was dynamically assigned when the routers connected to the provider. As a result, all local machines that access the network through this router seem to have a single public IP address (a kind of Network Address Translation = NAT) memory efficient—using as little memory as possible to perform an operation MIPS 4KC—a technology-specific implementation of the synthesizable 32-bit MIPS32 4KC core for building complex ASIC-based devices that is used to reduce design time, conserve resources, and shorten time-to-market modular design—separating the functionality of a program into independent, interchangeable modules, such that each contains everything necessary to execute a single aspect of the desired functionality name resolution—taking a name in one format and linking it to the name in another format e.g., an address such as 10.11.12.123 could be resolved to the name "Harry Harrison" NAT—network address translation nice'd to a very low priority— changes the scheduling priority of a given process packet forwarding—the relaying of packets from one network segment to another by nodes in a computer network primary thread—a software process. By default, every application has a single thread that is called the main or primary thread reliable messaging—the ability to communicate messages across an unreliable infrastructure while being able to make certain guarantees about the successful transmission of the messages routing—the process of selecting paths in a network along which to send network traffic rsyncs the source code image—rsync is a utility software and network protocol for Unix-like systems that synchronizes files and directories from one location to another while minimizing data transfer runtime module—when a computer program is executing a required task, the runtime module is the software package that contains the logic specific to the period during which the computer is performing the task runtime loadable module—contains the logic specific to the required task (e.g., utility grid, transit system, or tactical) single process—a process that has a single OS thread. A thread is contained inside a process. Multiple threads can exist within the same process, sharing resources such as memory; different processes do not share these resources. Single threads place the least demands on system resources such as memory and CPU cycles ssh—secure shell (SSH) is a cryptographic network protocol for secure data communication, remote shell services, command execution, and other secure network services between two networked computers. It connects a server and a client (running SSH server and SSH client program,s respectively) via a secure channel over an insecure network system shell interaction—a shell is another term for a user interface. This phrase refers to the interaction of the computer OS and the commands available to the user thread—a sequence of programmed instructions tunneling—transmitting one computer network protocol by encapsulating it inside another network protocol Ubuntu—a Linux-based computer OS unicast— a transmission that sends messages to a single network destination identified by a unique address VM—a virtual machine (VM) is a piece of software that allows operating systems to be run inside other operating systems |